The music reconstruction step is fairly straight forward. It does rely on connected components from the previous step.
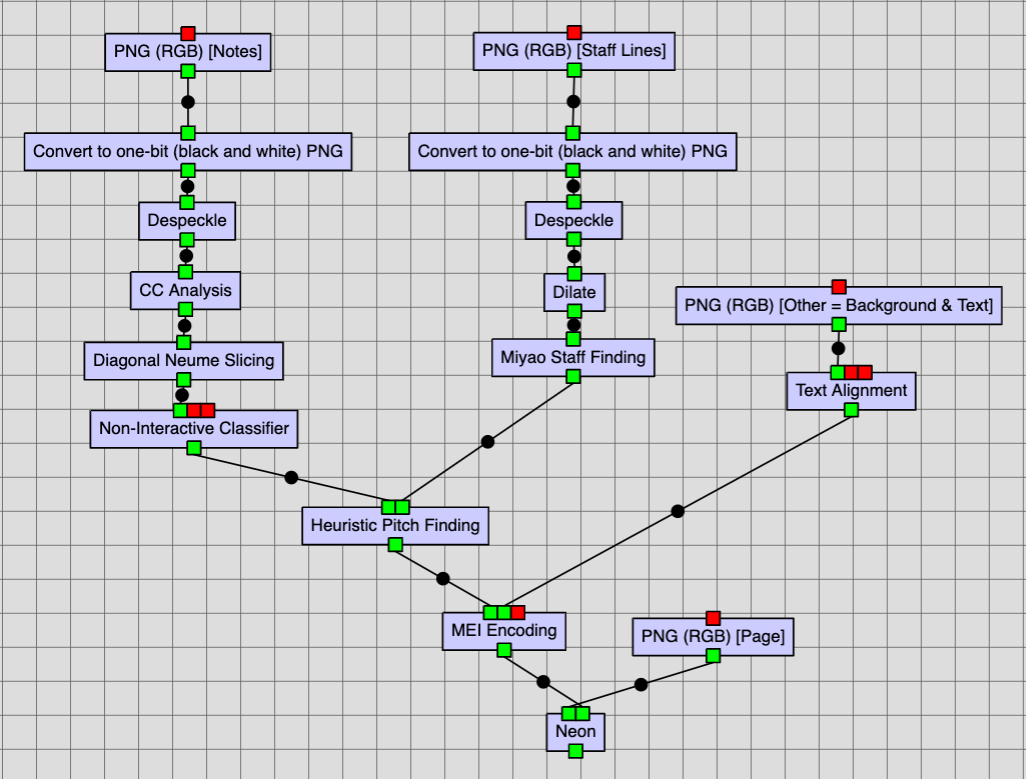
Miyao Staff Finding
The Miyao Staff Finding job uses the staff lines layer (see the document analysis step) and determines the characteristics of the staff/staves. It requires a specific black-and-white cleaned-up input image, much like the CC Analysis job previously.
Here, however, after despeckling the black-and-white image it should be dilated using the Dilate job to improve the results of the staff finding job. The steps to run the Miyao Staff Finding job are presented in the image below.
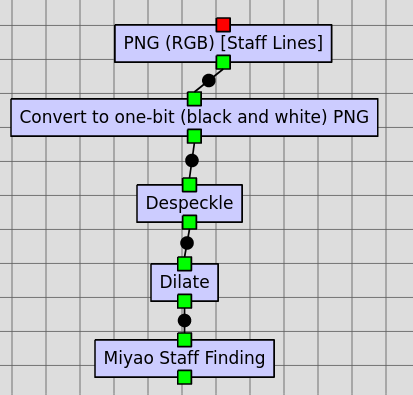
Heuristic Pitch Finding
The Heuristic Pitch Finding job combines classified connected components generated in this step with the staff information produced by the Miyao Staff Finding job. It produces a JSON file containing information on the glyphs, the staves, and the page itself.
A workflow showing the Heuristic Pitch Finding job using the results of the Interactive Classifier and Miyao Staff Finding workflows is presented below.
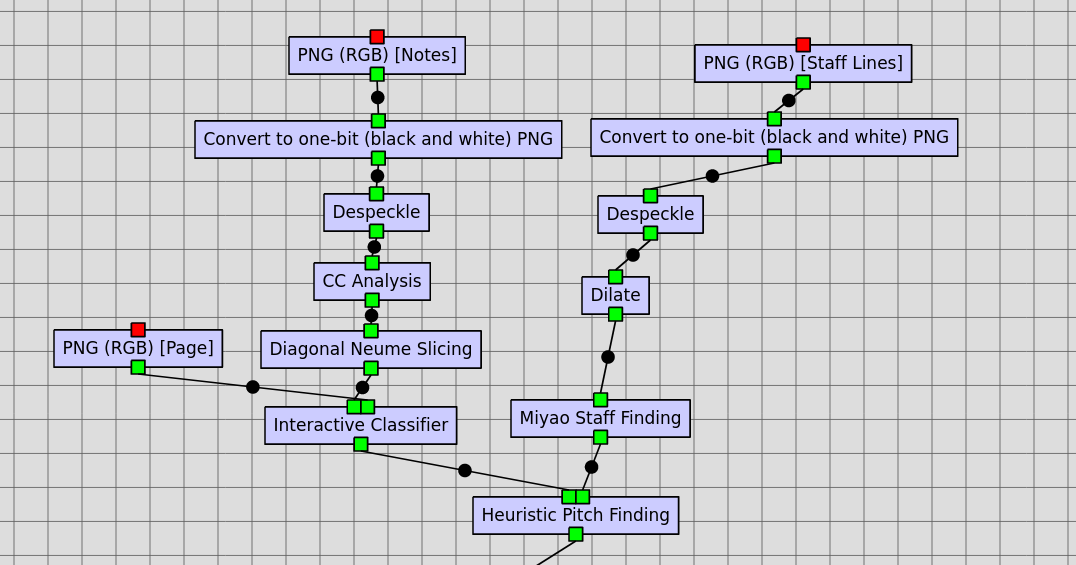
Text Alignment
The Text Alignment job is an optional step that allows the user to include the text of the source page into the encoded MEI. Specifically, this step takes a plain text transcript of the neumed text on the page, breaks it into syllables, and assigns these syllables to text on the page by using the text layer generated in this step.
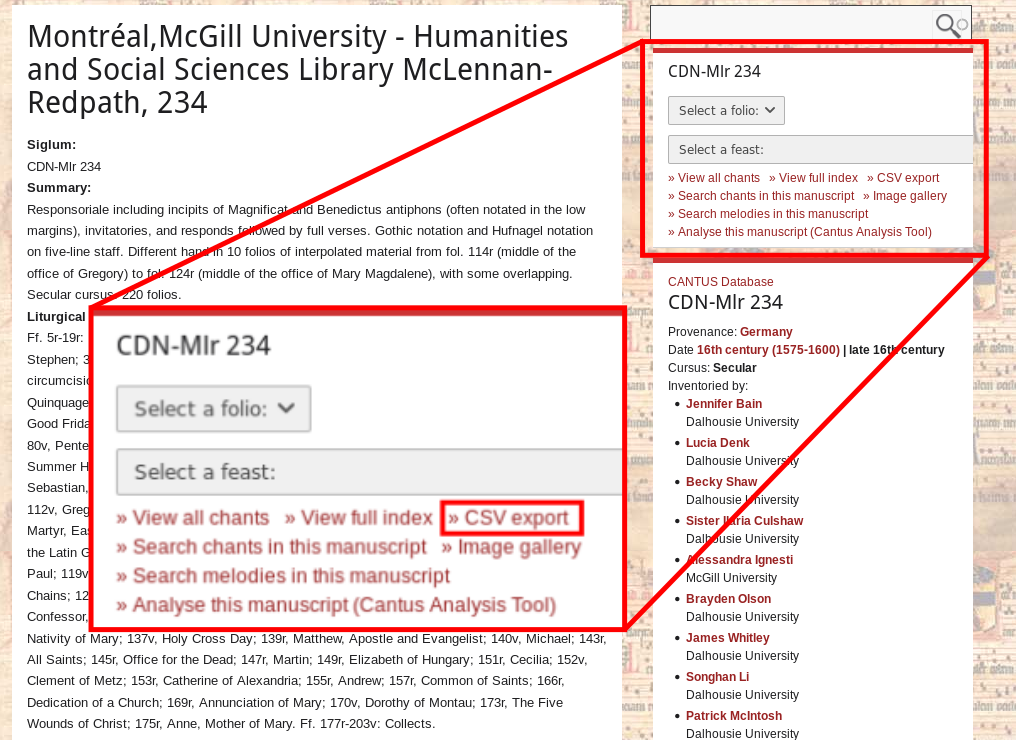
For many sources, the text can be obtained by using the Cantus Manuscript Database. The following steps can be used to obtain the text for a page:
- Find the source in the database.
- The siglum is the most direct way to find it, but many other options (e.g., provenance, description, century, etc.) can be used to search.
- Export as a CSV using the box in the upper right corner of the screen. The button “CSV export” will download the corresponding file.
- Open the CSV file in a program like Microsoft Excel or LibreOffice Calc.
- Locate the row or rows corresponding to the folio of the page. Often the last chant from the previous folio will continue onto this page, so it may be helpful to include that text as well. The text alignment job will discard text not found on the page.
- Copy the text in the row(s) under the heading
fulltext_msto a plain text (.txt) file. This is the input for the text alignment job.
The text alignment job also requires an OCR model. This can be generated by following the instructions on the job’s repository. Example models are also available under the models folder the repository.