Once the layers of a manuscript folio have been generated using the Fast Pixelwise Classifier and the models from the Patchwise Trainer, it is time to classify the music symbols. While the processing of text and staff lines is straightforward, the music symbols layer contains various neumes, clefs, and custodes that require additional effort to differentiate. For this, the Interactive Classifier can be used.
Steps Before the Interactive Classifier
The Interactive (and Non-Interactive) Classifier requires connected components, not just masks extracted from the source image. These are created by the “CC Analysis” job which takes a cleaned-up black-and-white PNG image.
For manuscripts wit diagonal neumes, the Diagonal Neume Slicing job can be inserted between the CC Analysis job and Interactive Classifier job where Diagonal Neume Slicing is run to split compound neumes into neume components, reducing the number of glyph classes to be classified.
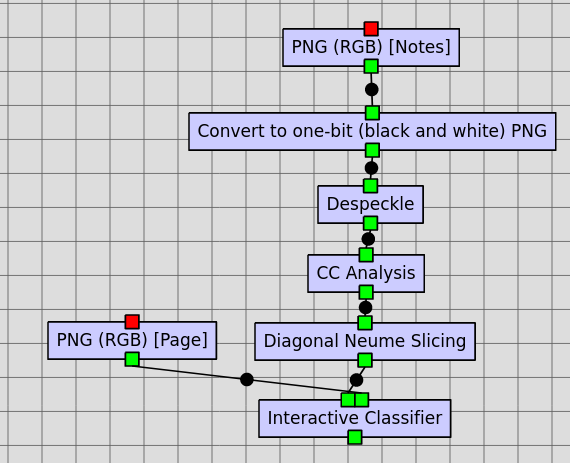
Above is a Rodan workflow containing the jobs necessary to prepare the inputs for the Interactive Classifier.
Interactive Classification
The Interactive Classifier allows the glyphs from the music symbols layer to be classified as different element types. Typically, the naming of these classes follows a hierarchy. For example, a C clef would be classified as clef.c and a punctum would be classified as neume.punctum. However a custos would simply be custos.
The names of these classes must correspond to names in the mapping file (CSV) to be used in the MEI Encoding job. Such a mapping file can be produced with the MEI Mapping Tool.
Even with good layer separation, there will still be specks around the music symbols of interest, and these should be ignored. Rather than attempting to these small connected components by hand, an alternate approach is to just classify them as skip so they are detected and filtered out by the automatic classification phase(s). Otherwise the classifier will attempt to classify them as something like a clef or neume, regardless of the confidence level.
There are two main ways of classifying neumes: a neume-based approach and a neume component-based approach. The former will attempt to classify entire neumes (e.g., neume.clivis.3) as described on the Interactive Classifier wiki. The latter approach uses the diagonal neume slicing job and then only classifies neume components by the shape of the note head (e.g., neume.inclinatum), handling neume grouping later in the workflow. This approach is typically better for square-notation documents as it is possible to quickly get much more training data for the smaller set of neume component classes compared to the many possible neumes that can exist.
Using the Non-Interactive Classifier
The Interactive Classifier is wonderful for getting started, but it would be much more convenient (and faster) to use an automated classifier that already recognizes the different classes. Luckily, the Interactive Classifier allows us to prepare the resources for this. There is a non-interactive classifier job which takes a set of connected components to classify, much like the Interactive Classifier, but also requires a set of training data used to classify the connected components. It can also optionally accept a set of feature weights produced by Biollante.
Of course, a single page likely does not provide enough training data on every kind of glyph that may be encountered in the manuscript. Training data can be added as an output from the Interactive Classifier, but then used again as an input on another page allowing for more training data to be generated. Once enough examples of different glyphs have been provided, the training data output from that job can be used in the non-interactive classifier job.
Note that the Interactive Classifier job is also capable of accepting training data and feature weights as inputs.
Note on Using Biollante
The Biollante job is an optional part of this process. It attempts to optimize the features used in the classifier based on training data. Training data can be obtained from the Interactive Classifier through an optional output port.
After Biollante is run (for details see the overview page on it and links there), feature weights or feature selections (i.e., weights for features are restricted to {0, 1} rather than [0, 1]) are generated. These can be used as inputs to the Non-Interactive Classifier job along with training data and unclassified connected components.